
Python Project
Instacart Grocery Online
During one of my courses at Career Foundry, I had a project that introduced me to Python. This project was key because it allowed me to apply my analytical skills for performing exploratory analysis in a large dataset.
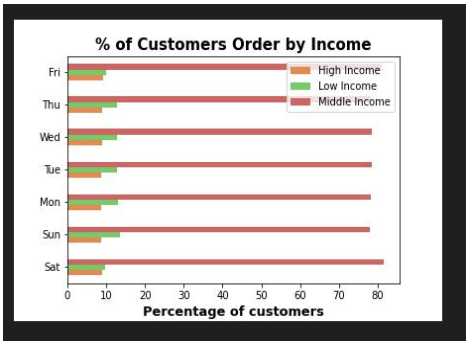
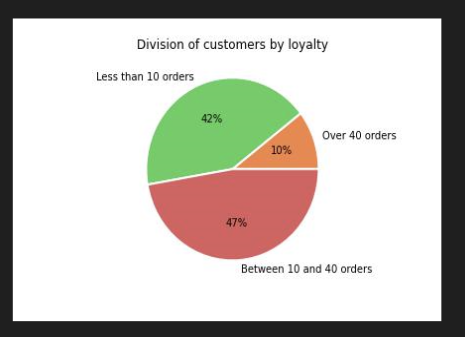
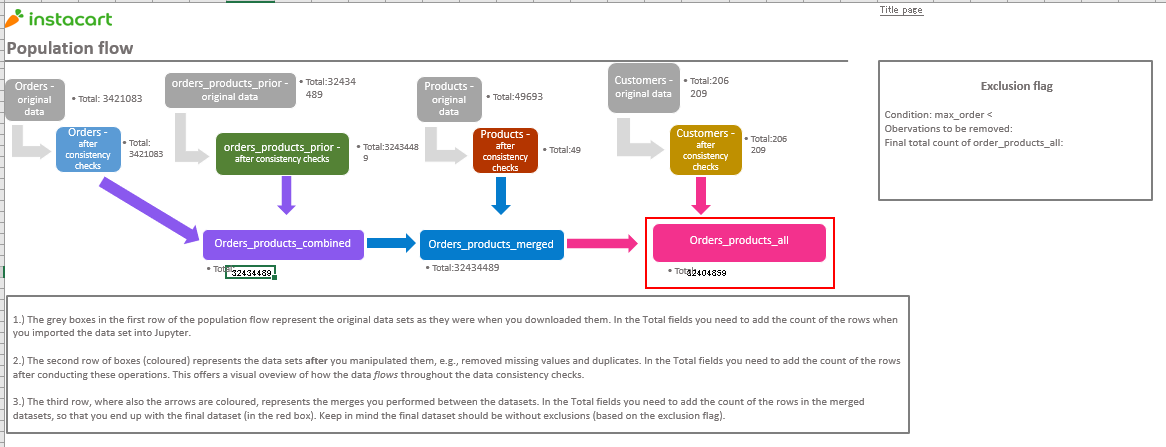
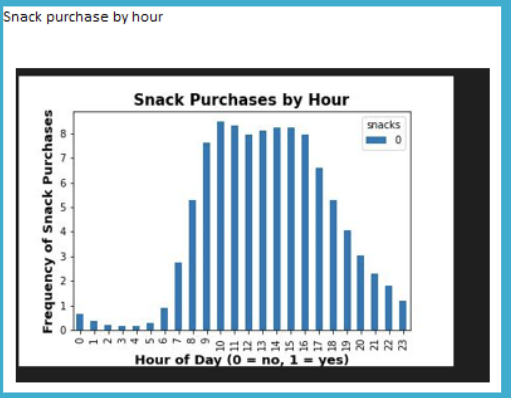
Context
As a Data Analyst studying at Career Foundry, working with GameCo data, I performed a descriptive analysis of a video game data set to give a recommendation of how budget should be allocated.
Objective
Analyzing sales patterns, performing exploratory analysis, and deriving insights for a better segmentation for an online grocery store, Instacart. The company is interested in understanding the purchase behavior from their customers, so they could deliver better targeted marketing campaigns. My role as Data Analyst is to give a recommendation.
Goal
Deliver a final report including tables and visualizations that profile Instacart customers based on their purchase behaviors. Using the tools, skill sand methodologies learned throughout the course at Career Foundry e.g. Python and relevant libraries.
First step- Data Exploration and Data Cleaning
As a first step I needed to clean the datasets. As with any project, avoiding this step might lead into weird or misleading results in your analysis. Python is surprisingly good at doing this job and is incredibly fast. This step consisted in cleaning 3 data sets (orders, customers and products) was straightforward and it followed the classic methodology of ensuring data is in a consistent format, there are no unexplained missing values, and there are no duplicated records.
Second step- Data Analytics
This is where things start turning interesting. Once I merged the datasets, I was left with a unified version of almost 30M rows and 30 columns! Quite a lot when it is your first time trying to handle this massive amount of data. To give you a brief idea, this dataset contained information in the orders each user had done, the time and date of purchase, the product’s name, the department the product belong to, and demographic information from customers (age, income, state, family status, number of dependents).
Third Step- Insights and Data Visualization
From this step on is where I understood why pandas (the library of Python I used for this project) is a better option when dealing with big datasets. Normally, in programing languages when trying to categorize something, you need to evaluate logical conditions and iterate these conditions to every row in the dataset. Doing this is the same as trying to apply a formula to numerous cells in Excel and your computer screen freezes. Thanks to the magical loc function I was able to segment Instacart customers into 15 different profiles based on family status, age, income, and number of dependents.
Example of Code to create the segmentation of single customers
# To create the customer profiling for single people, we included 4 subprofiles based on income and age. # The age and income numbers were determined by the approximate of median calculated before df_opc3.loc[(df_opc3['fam_status'] == 'single') & (df_opc3['Age'] < 38) & (df_opc3['income'] < 85000),'profile_flag'] = 'Single young adult low income'
Final step- Analyzing and Visualizing
This final stage of the process is where I extracted most of my future learnings and practises from Python. Analysing the data is all about grouping variables and applying a statistical criteria. For instance, finding out the average spending or the count of orders made by each of the 15 profiles I had suggested in the step before.
Visualizing was tricky. If you used a matplotlib is simple process and the kernel- the engine that executes the code- will probably not crush. If instead, if you use seaborn, a more specialized library of Python for making statistical graphs, then the memory of your computer will reach its limit. Solution? Taking a representative sample ( in my case I took 30% of the total population). This is particularly important if you want to go deeper into making interesting visualizations. At the end, I was lucky to make two graphs, and this was the furthest the computational power of my machine could go.
Final Recommendations
Despite the challenges encountered and the ones that will remain as future tasks, these were the four key outputs extracted from all the data: As the company is looking to improve targeting for their ad campaigns it is important to have in mind that the most dynamic segments are married customers with more than one dependent in regions such as the South of USA. Therefore, any efforts applied to these segments should be focused on increasing the average spending per order as opposed to the number of orders. If the objective is to increase purchases, then is better to target segments such as young adults with high income, so they can increase their number of orders. It is a good idea that the marketing campaigns start funneling new users into turning them into loyal or regular customers by offering lower prices. Because the categories of higher rotation are the fast consumer good, perhaps to boost the sales of other categories a cross promotion could work well. For example, bananas, which is the best selling product across all customer profiles could work to incentivize purchase in other products from other departments.